An evaluation of Kagi
I saw a post this morning about Kagi, and I am honestly kind of intrigued about its whole concept.
The big idea is that instead of using an ad-supported search engine, you pay for your web search, and you get better, more private, and less filtered results. If the only person financing them is you, then they are incentivised to improve their service to you. If advertisers finance them, they are incentivised to act towards the best interests of advertisers.
I am kind of tired today, so something relatively low effort compared to coding or something is a nice idea. Let’s test them out!
My criteria
I have two main things I care about in terms of a search engine: results, and ergonomics. Privacy is nice, and why I use Qwant currently, but if Bing (its result provider) was not also up to scratch, I would not be using it.
Results are just how relevant and helpful its responses to my search are. Ergonomics are everything else about a search engine - how is the UI? How are its fast inline responses to questions (calculators, currency & unit converters, images, maps, shopping results, Wikipedia pop-ups, extracts from websites, Google Knowledge Graph, shudders AI LLM responses (Bing Chat), etc.)
And also the ergonomics includes one particular feature that I use a lot that is not very mainstream: shortcuts. Your search engine is bound to your browser search bar, and while sure, many browsers make using alternative sites easy, having it built into your primary engine is something I’ve grown used to.
DuckDuckGo (who I’m pretty sure popularised the idea) call them bangs, and Qwant calls it Qwick.
How much search does one need?
Kagi is a paid service, and to make the relatively unappealing prospect of paying for something that has been free for almost the entire existence of the Web more palatable, they offer tiers.
Kagi’s base rate is $10/mo, which they explain in this blog post actually loses them money on average.
They offer a half price tier at $5/mo for a cap of 300 searches per month.
I exported my Firefox history, filtered to the past 12 FULL months (01 Sep 2022 - 31 Aug 2023), filtered out duplicate searches, and divided by 12, to give me that in the past year, I made 102.667 searches per month. If you include Qwick uses (If I search &w french toast it takes me straight to the Wikipedia page for, well, French toast!), then that rises to 107.583 requests per month (Some Qwicks are double-counted as it converts from this%20format to this+format).
I will be testing using their free trial tier, which is presumably designed so that people like me can actually see if its worth spending $5 to search. It is a one-time option, so here goes.
If you were wondering how I ran the numbers on my Firefox history, I opened the places.sqlite file from my profile (after making a backup!) and used this method to dump the table to JSON. I then loaded up the Deno REPL and wrote a little code there.
So! 300 searches a month? Their service better be really good if they think I’m using it nearly 3x as much as I search currently (…according to my dubious methodology!)
First impressions
Their onboarding, as well as giving me a “just go to search” button, funnelled me into a very nice customization flow.
I set my country, colour scheme, left vs centred results, favicon on/off & position, url style, url placement, and new tab preference.
Setting the country actually did not save though, so I re-set it in the options later.
I wish Kagi out-dented the favicons, like Qwant does, as it makes it a lot less scannable with them inline with the URL. On Qwant the favicons almost act like bullet-points in a list.
They wanted me to install an extension to setup my default search engine for me, but to be honest, I don’t really like that idea, so I just set it via opensearch like normal.
Their advanced search is nice, as well as images, videos, news, podcasts (interesting!), maps, you can search via Wikipedia, Wolfram Alpha, Youtube, Google, Bing, and Google maps.
You can add more shortcuts with custom name and URL (Chrome-style, with a %s placeholder), AND A CUSTOM BANG. Oh, yes. We’re on for shortcuts.
Time filters are very specific, country filters are as usual, and sort order supports: “default”, time, “website” (?), or number of ads & trackers. Neat.
I dig the design for what that’s worth. I guess I should try it then.
Ergonoics
These are easy to test fast, and jump out at you quick, so let’s start there.
Calculations and anything on Wikipedia will show in the search suggestions bar without even needing to hit enter, but hitting them still just searches as usual.
A very Google Knowledge Graph -eqsue panel appears with data from Wikipedia, a picture, summary text (eg “American Actor born 1962”), fact file things like birth date, occupation, spouses, etc. It also linked to IMDb and Rotten Tomtatoes for my test subject, Tom Cruise.
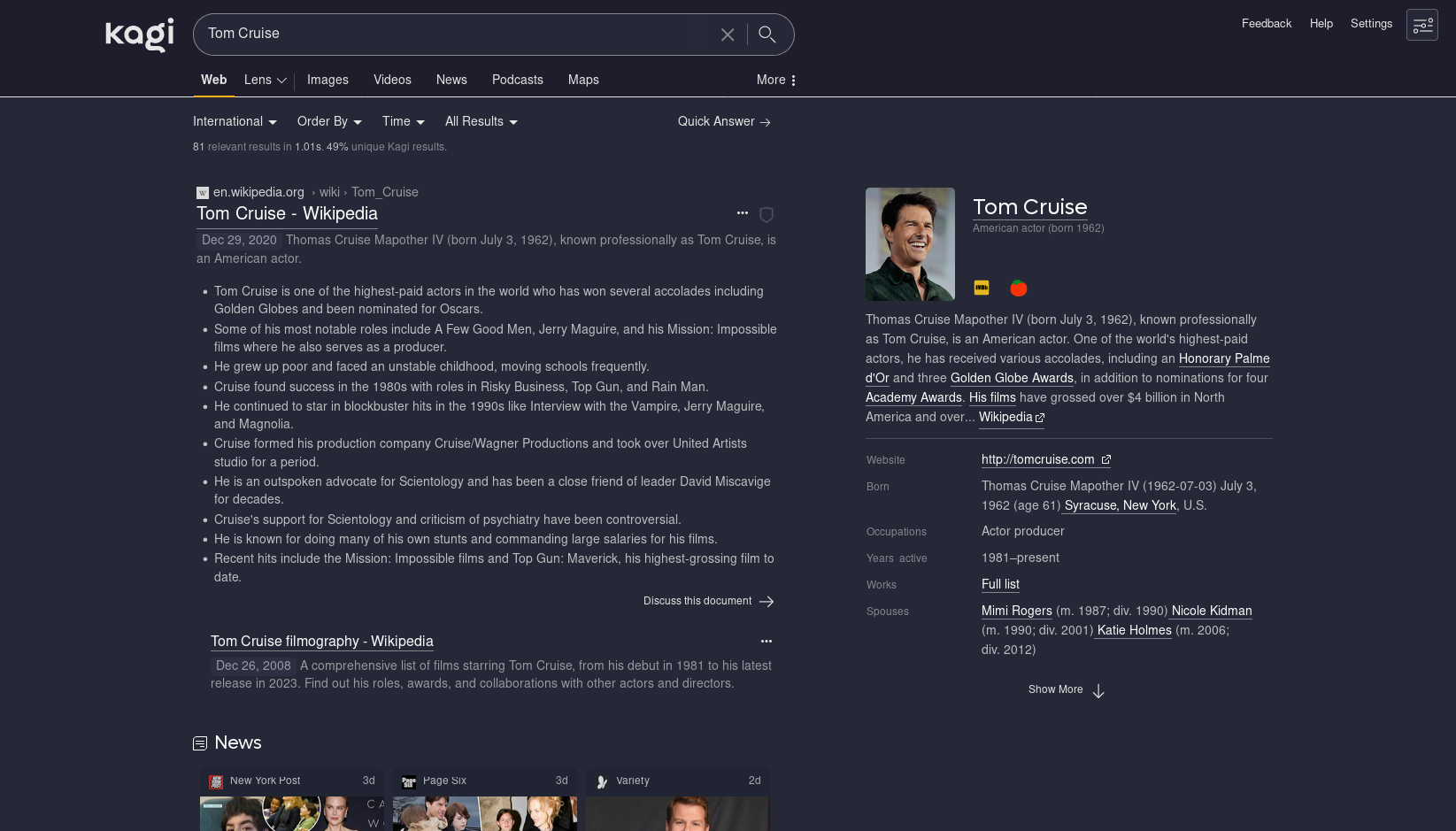
The results are structured very cleanly, with each part of the result visually easy to tell apart, a dropdown to select options like “more of this site” or to summarize the page for you (it does this with AI, inline, and produces a bullet-point digest of the result, cool.)
There’s a shield icon you can hover over to display more info about the page, let you adjust the domain’s search ranking to your tastes, and if the site uses https or not.
Sub-pages of a result show indented underneath it, which is neat. Having Tom Cruise’s filmography on Wikipedia show under his main WP page is a nice touch - its relevant but also structured nicely.

A news section is not really my preference for showbiz stuff but its a decent enough selection for most people, and generally everything is well structured.
The have a “Quick Answer” feature that uses AI to pull together a summary of my search into one place. It lists its sources, which I appreciate.
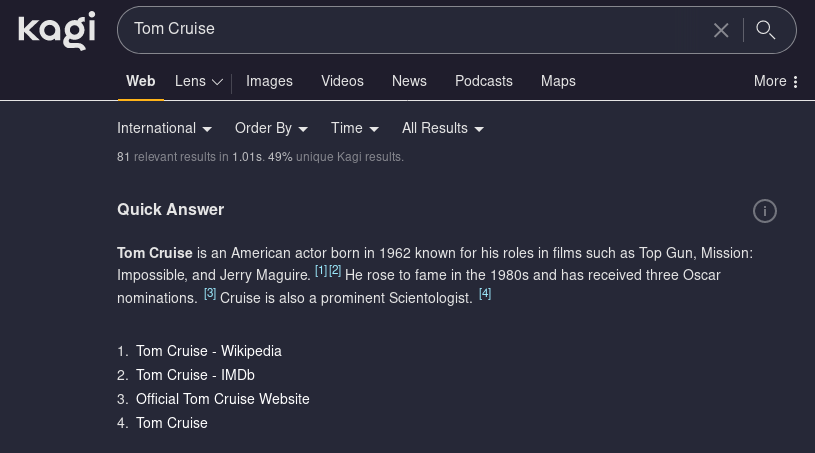
Calculations, unit conversions, and currency conversions are all a breeze, though it’s all handled by one ‘computer’ widget, so no currency history graphs like Google.
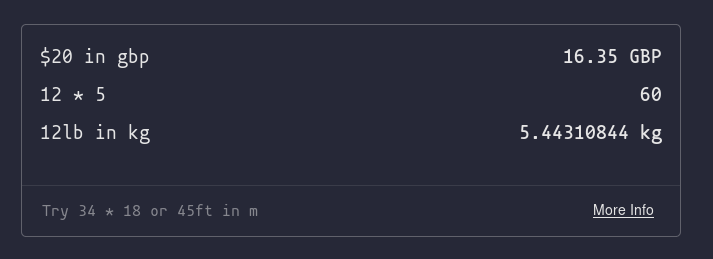
It is a pretty sophisticated widget though, supporting all sorts of fun math things. You can use _ to use the last answer. Their more info tooltip claims it can sort arrays, but it failed to.
Translation works as well as you’d expect.
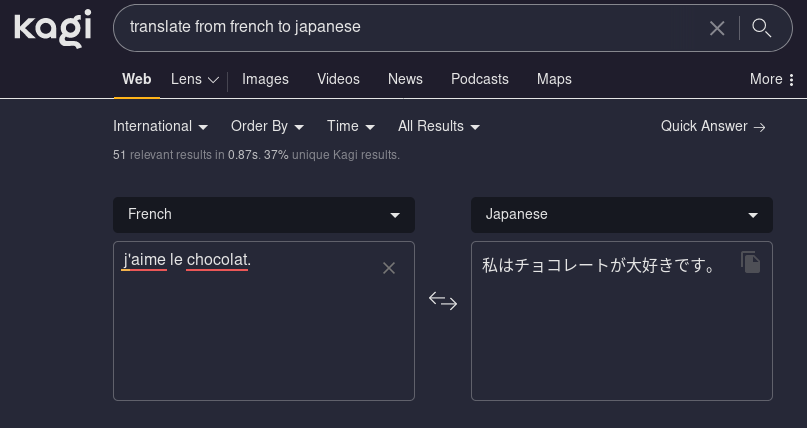
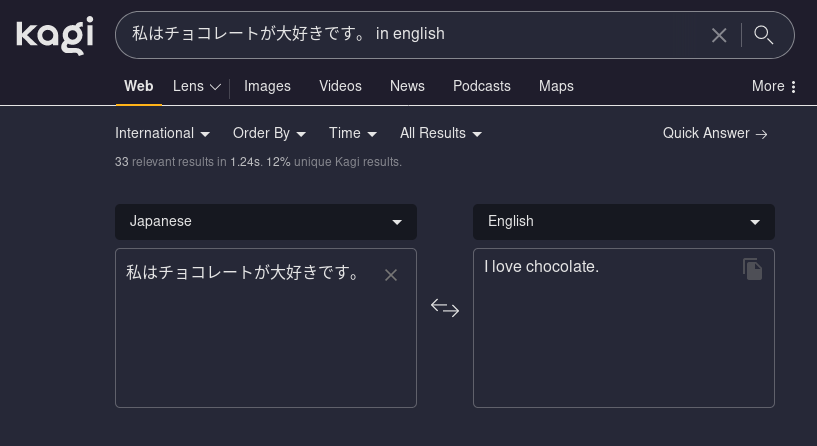
Bangs autocomplete in the search bar (along with very localized looking results, makes sense given I chose that), and work just fine direct from the Firefox search.
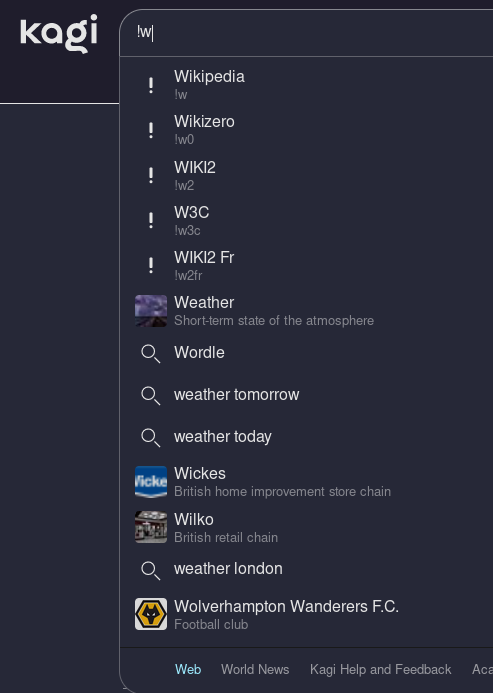
Extra points go to their Wiktionary search (!wt) working properly, Qwant’s (&wt) does not work.
Results then?
Test 1: “deduplicate array JS”
My reference was Qwant, which gave me to-the-point results:

Kagi showed that StackOverflow post with simple code solutions in a sidebar, which is very helpful! Cool.
It found the same SO link, extracted a few answers from it directly, which is nice, but showed tons of other similar SO questions as sub-results, which filled up my entire screen.
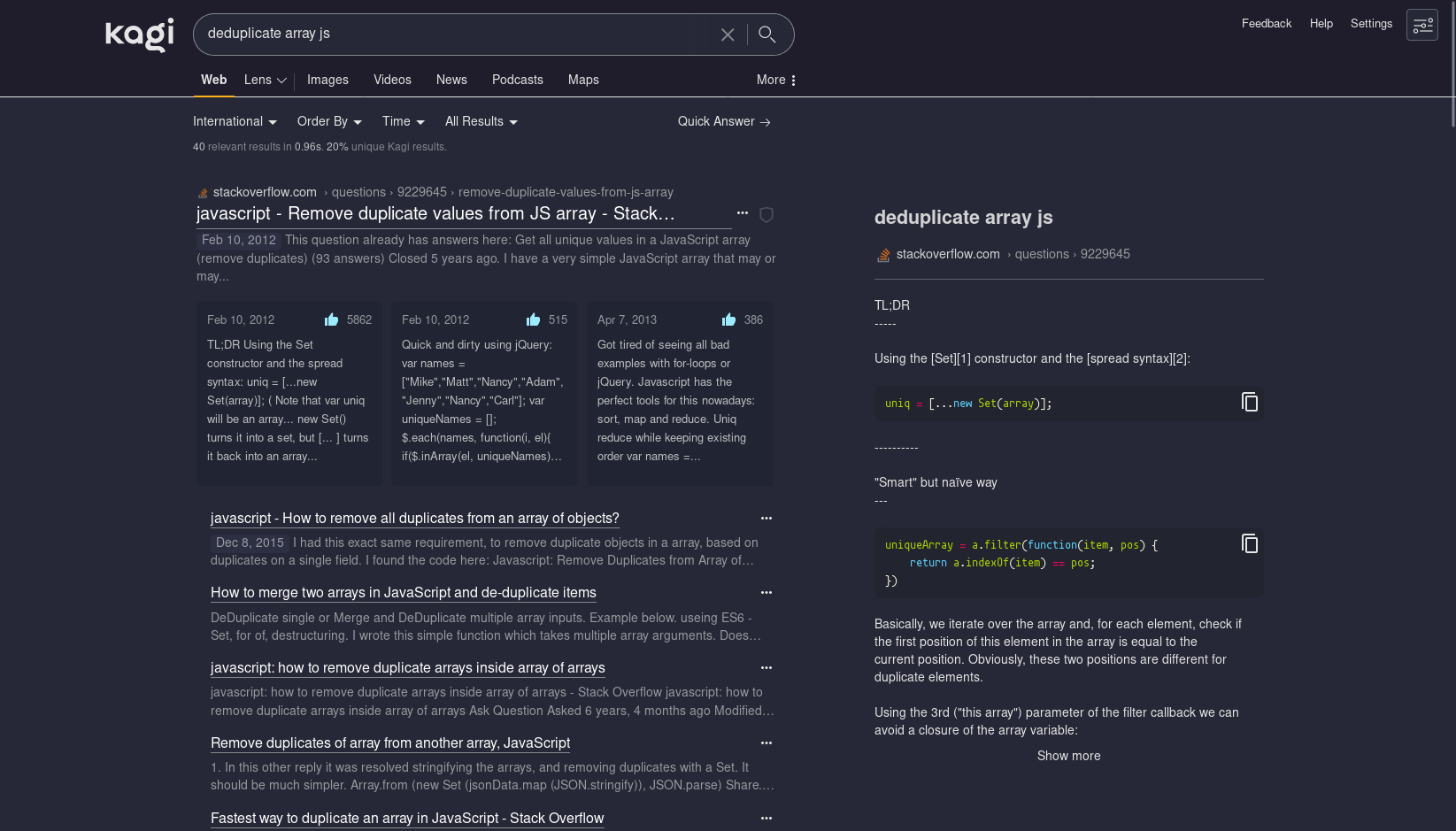
Scrolling down, this seemed a pretty common trend, as it expanded one sub-result per result. Useful to move further with my searching, but not good for seeing as diverse as possible results fast.
I suspect I would like this a lot more on, say, Reddit results, though.

Google finds some weird middle ground here, with unnecessary video results, a plain worse attempt at picking out SO answers, a “people also ask” section with… the same question I asked 4 times, but “fine” results.
Clear winner: Kagi here. Qwant finds similar results, but Kagi gives me my answer straight away.
Test 2: “best pizza recipes”
Starting with Qwant as my reference, we get a selection of alternative queries for home made pizza, a list of recipe websites, and some videos about how to make pizza.
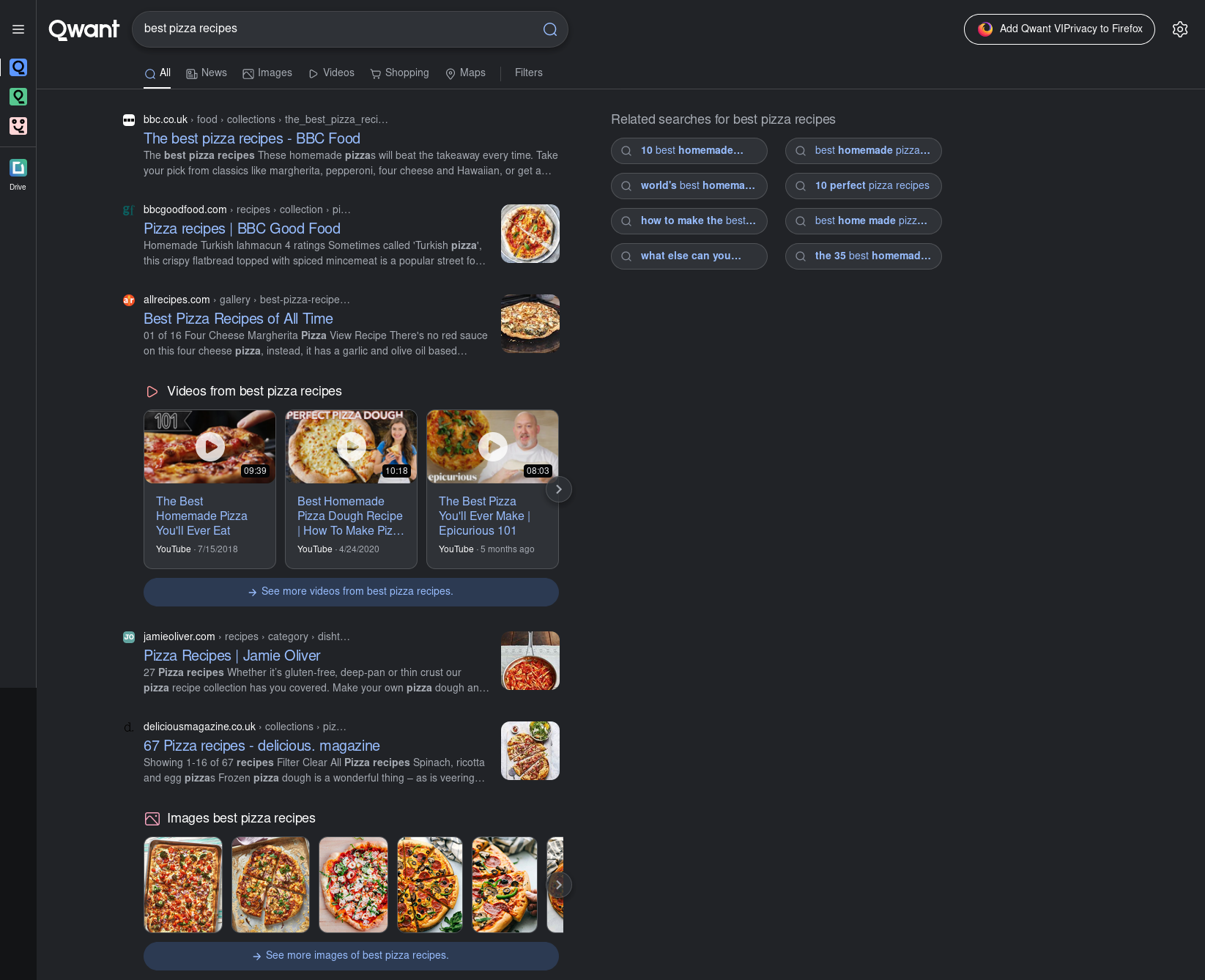
Kagi’s response to the same query was first to show me “Discussions”, which honestly just look like normal results to me but displayed weirdly.
It then proceeded to fetch more pizza recipes, some videos, and some images too.
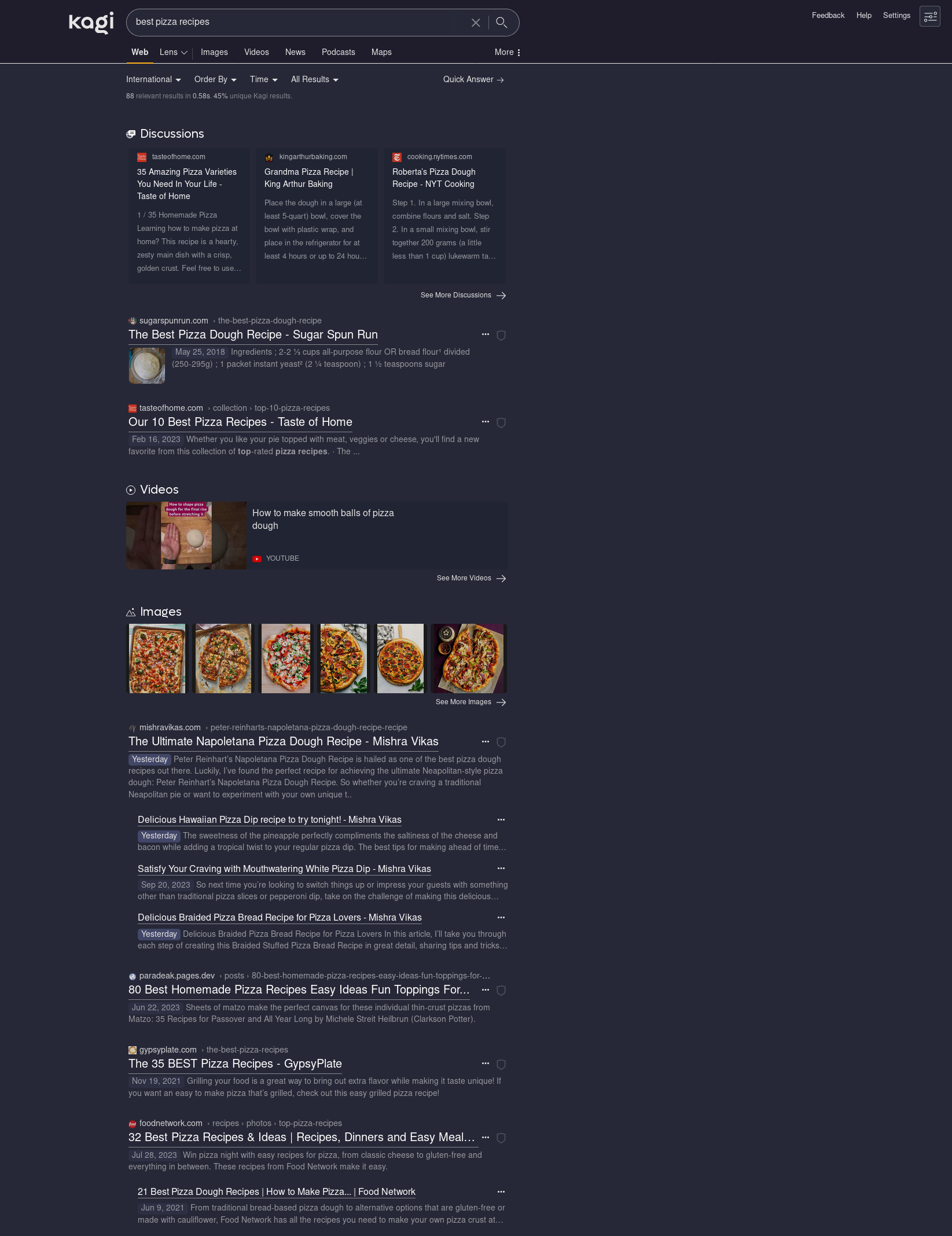
Interestingly, here we see that shield button play much more of a role: it tells us that allrecipes.com has a lot of trackers and what kind, gives us popularity info, the language, domain date, website speed, and tells us that it’s owned by Meredith Corporation.
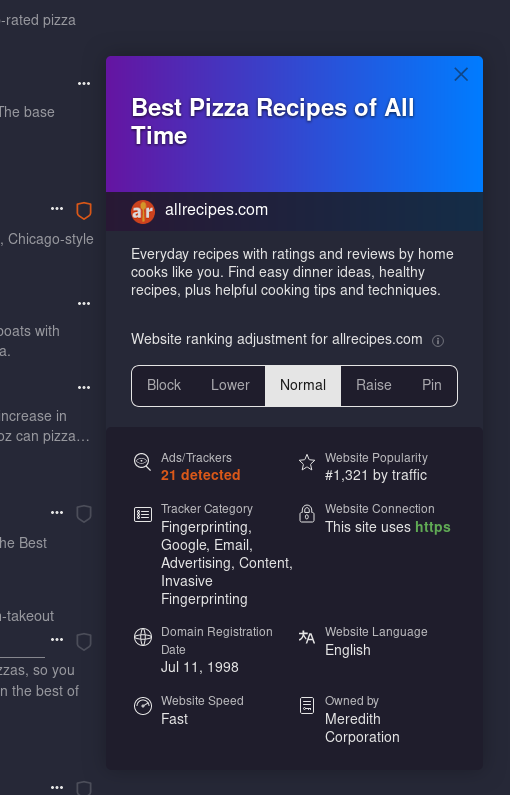
It seemed to give me a lot more results about making dough than pizza as a whole, interestingly.
Qwant served me United Kingdom-centric results by default, hence BBC Good Food and Jamie Oliver, etc.
Kagi did not, and I don’t really recognise any of the result websites. Changing my country to the UK in the dropdown, I get BBC at the top, which is good, though still some unusual picks, and Discussions are still… not discussions.
It’s interesting to see a *.pages.dev site rank high, as that’s a free web domain handed out by Cloudflare for using their site hosting service. I don’t quite know whether to find that negative as a low-credibility result or positive as a much more independent and fair search result than requiring a big professional domain name.
I’d want to lean on the latter normally, except the page itself is absolutely useless, just describing each kind of pizza advertising style, with no actual recipes. Not good.

Trying Google, the first thing I see is a big “Recipes” panel with nicely presented links. The results seemed solid enough, “People also ask” showed relevant questions, it suggested related searches for specific kinds of pizza with pictures, and honestly just seemed very geared up to answer this kind of question well.
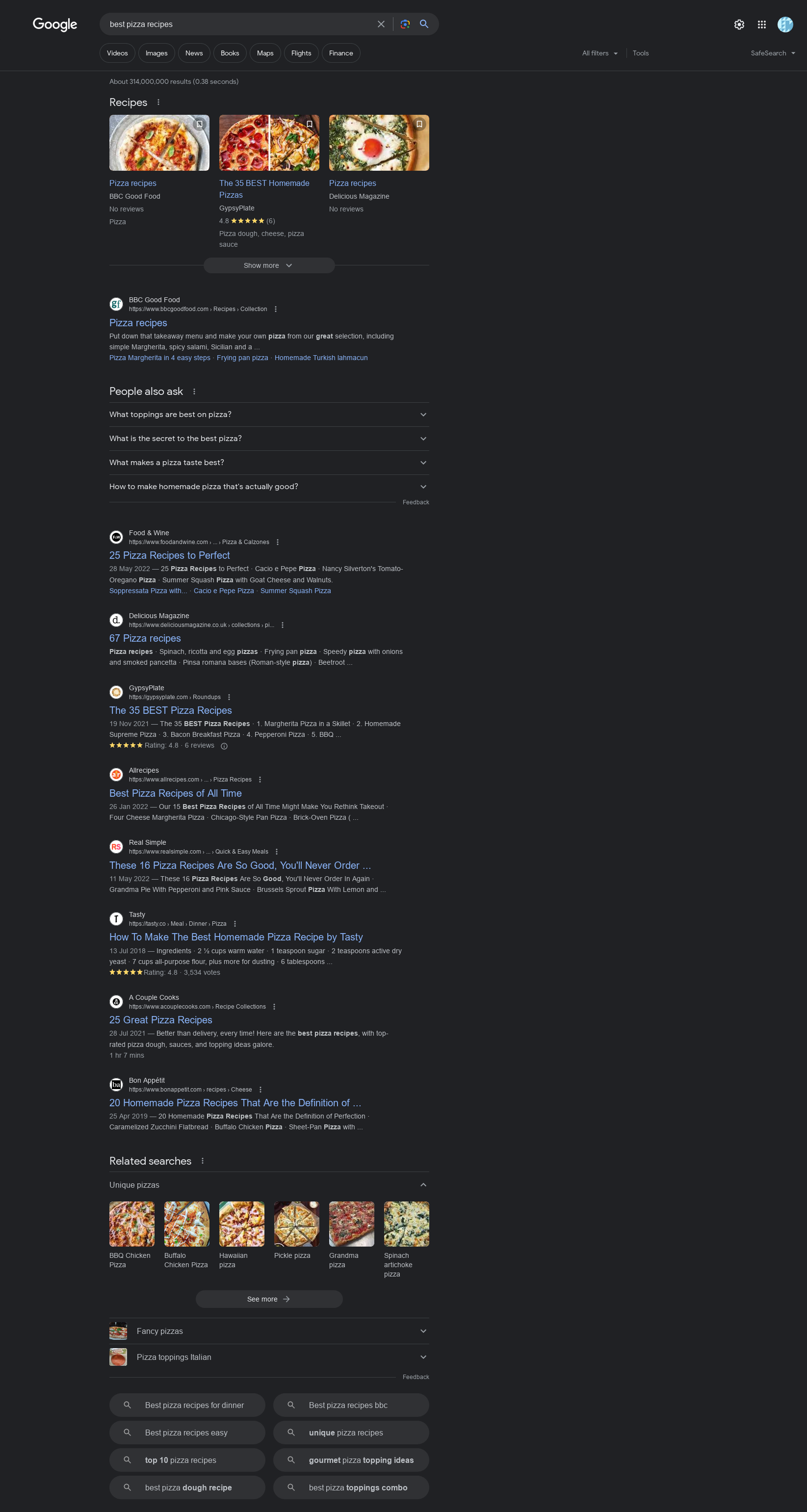
Winner: Google by a landslide. Qwant beats Kagi by a small amount.
Kagi’s findings were not bad, and never repeated themselves which is actually quite nice, but Qwant provided to-the-point and reputable sources, and offering good video results was pretty on-point here too.
Google might not have pushed for video recipes, but its results were incredibly tailored to the type of question, and if I was just looking for the best damn pizza recipe to make, this would be by far the most helpful to me.
Test 3: a couple random bits
I went to grab some images for a stupid edit, and noticed that Kagi showed Apple Maps for nearby places to go horseriding, which is pretty neat.

Also b r a i n s.

Winner: nobody really.
Test 3: “best value gym”
This one I have some criteria for what counts as good: fulfils my search of good value, is a UK-based gym (All of them know my country), and bonus points go for showing gyms near me (they all have my IP, and can ask for geolocation if they really want it lol).
Granted in the real world I’d probably use a combination of searching with a maps service to find the best solution close to me, but hey, why not show it inline, its relevant enough.
It was at this point that I discovered Kagi had not saved my country preference from on-boarding, so I re-set that before searching this.
The only one to ask for accurate geolocation access was Google.
Starting with Qwant again, I got results from a mix of highly reputable sources (moneysavingexpert, goodhousekeeping), some I didn’t recognise such as moneybright and homegymexperts, and one result that was actually a gym trying to sell me their subscription (1leisure).
Not awful but I’m not hugely impressed.
Kagi continues its trend of “Discussions” being not actually discussions but otherwise fine results. Its top result, like both other engines, is MoneySavingExpert, nice.
Its second result is for Crunch, a gym trying to sell me a membership, not so good. Kagi then decides to show me a condensed view with lots of Listicles, and while this is honestly a pretty good idea for this kind of search, these seem to be mostly America-centric, with two of them saying NYC in the title, so failure on regional results for the listicle widget.

The other results were “eh, fine”, but with a few more gyms managing to get their pages in the list than others. The page summaries let you mostly filter this out manually, but it’s not ideal.
It also returned an OpenAI blog post called “Safety Gym”, which is absolutely nothing to do with my search.
Google asked me for geolocation as mentioned above, and then went ahead to list by far the most useful results. It put MoneySavingExpert top again, but then listed student-focused sites, and The Guardian as well, which now I’ve seen it seems like an obvious omission from the others, however PureGym do get their site on the list.
Scrolling down, Google shows me results for local gyms on a map, too.
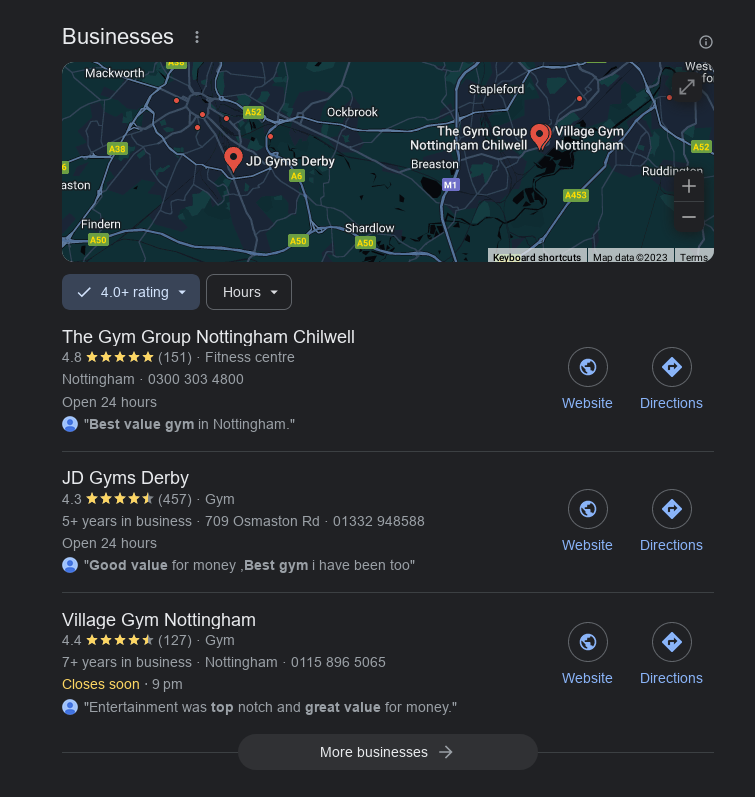
Winner: Google by just a bit - its results were the least infiltrated by gyms, but were mostly on par with Qwant.
Kagi loses again quite hard on having the most gyms advertising their membership instead of comparisons, and lists many American (especially New York) based results.
Reverse Image Search
This is kind of an odd inclusion, but I sometimes need this, so I’m interested to see how Kagi holds up.
I’m going to test some art, and a picture of a place.
I’ll be testing Kagi, Google, Yandex, and Bing.
My test art image is this: https://pbs.twimg.com/media/FvQUJ0jaYAAtN0-?format=jpg&name=large And also a version downscaled to 480x597px and compressed to JPEG quality 30. Yes, its brutal.
My test place image is of Heidelberger Altstadt: https://i.yellows.ink/54b493f51.jpeg
{kind=link}
Same compression applies, image size is already 512x341px so left as is.
The reason for the two tests is that art is usually quite identifiable, but I want to find the source of it. Places can look much more alike to each other, but the actual source doesn’t really matter to me.
Having the exact picture I have found elsewhere is what I’m aiming for, but if I just wanted to know where the picture is, having other pics of the same place is acceptable as well.
They test differing levels of uniqueness and corresponding strictness.
Test 1
Kagi found a lot of very similar images for the art full res, and after scrolling for a while it did find it! Though it was from a different tweet by the same artist, it found the image so whatever.

Testing with the compressed version, it also found it, though it found a retweet of the original artist, interestingly, and further down.

Now for Google Lens! I did not even have to press the “find image source” button for it to list the source as the top hit.

The same was not true of the compressed image, and pressing “find image source” found nothing.

This is a failure for Google, it did not find it.
Next up: Yandex. Yandex are generally the reverse image search king, so let’s see how they do!
They didn’t find “any other sizes”, which is unusual for them. They found much less popular in the west results for sites where the image is used.
Clicking through to similar images, Yandex was another fail, unfortunately. Plenty of anime girls but not the one I want.
Testing the compressed file for shits and giggles, I got similarly useless results.
Finally, Bing. Bing isn’t usually an engine I bother with for reverse searching, but I’ll try. Bing, like Google, found it from the originally instantly.
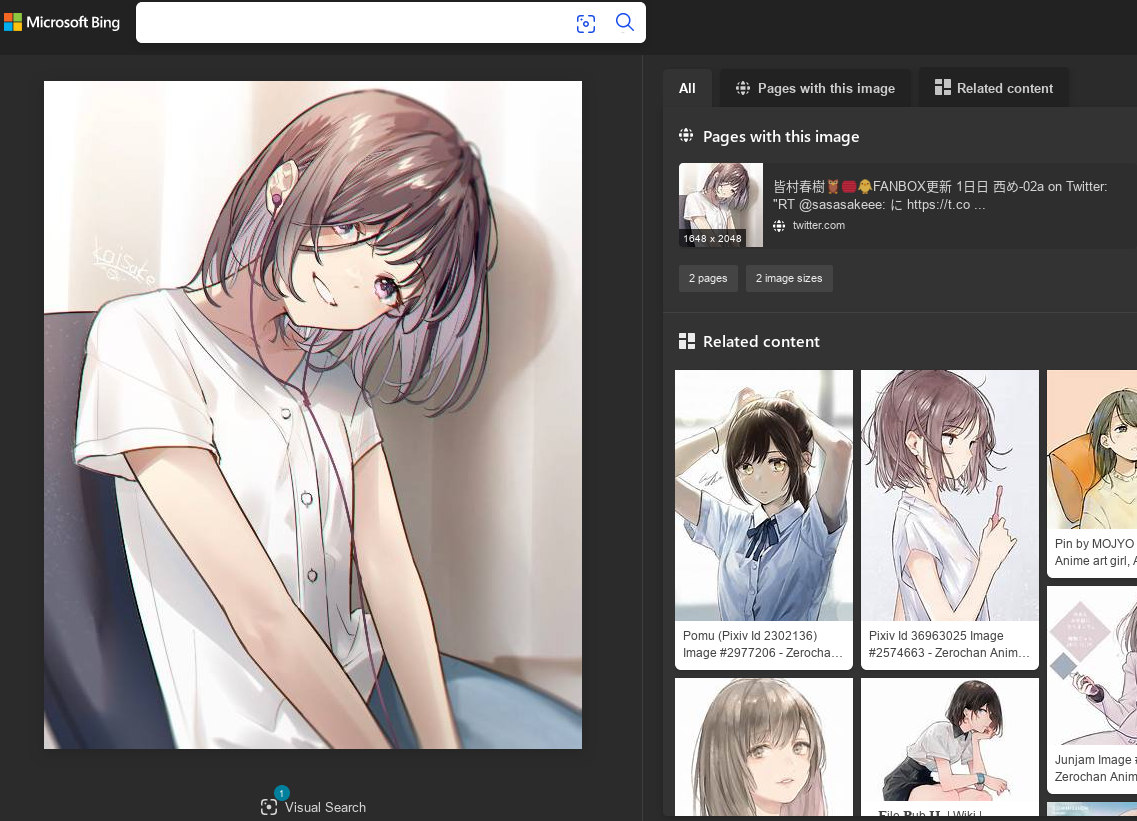
Bing gets the landslide win here, as it found it as if nothing was even amiss when compressed! (look closely and you can see that the picture is indeed heavily jpegged)
Test 2
Now to find Heidelberger Altstadt!
Starting with Kagi, it found the image I was using as the top result, and also showed exclusively other images of similar views of Heidelberg. A pretty perfect win here.
Looks like somebody took this photo off of Google Maps and uploaded it to Pinterest! Because that’s where Kagi found it.
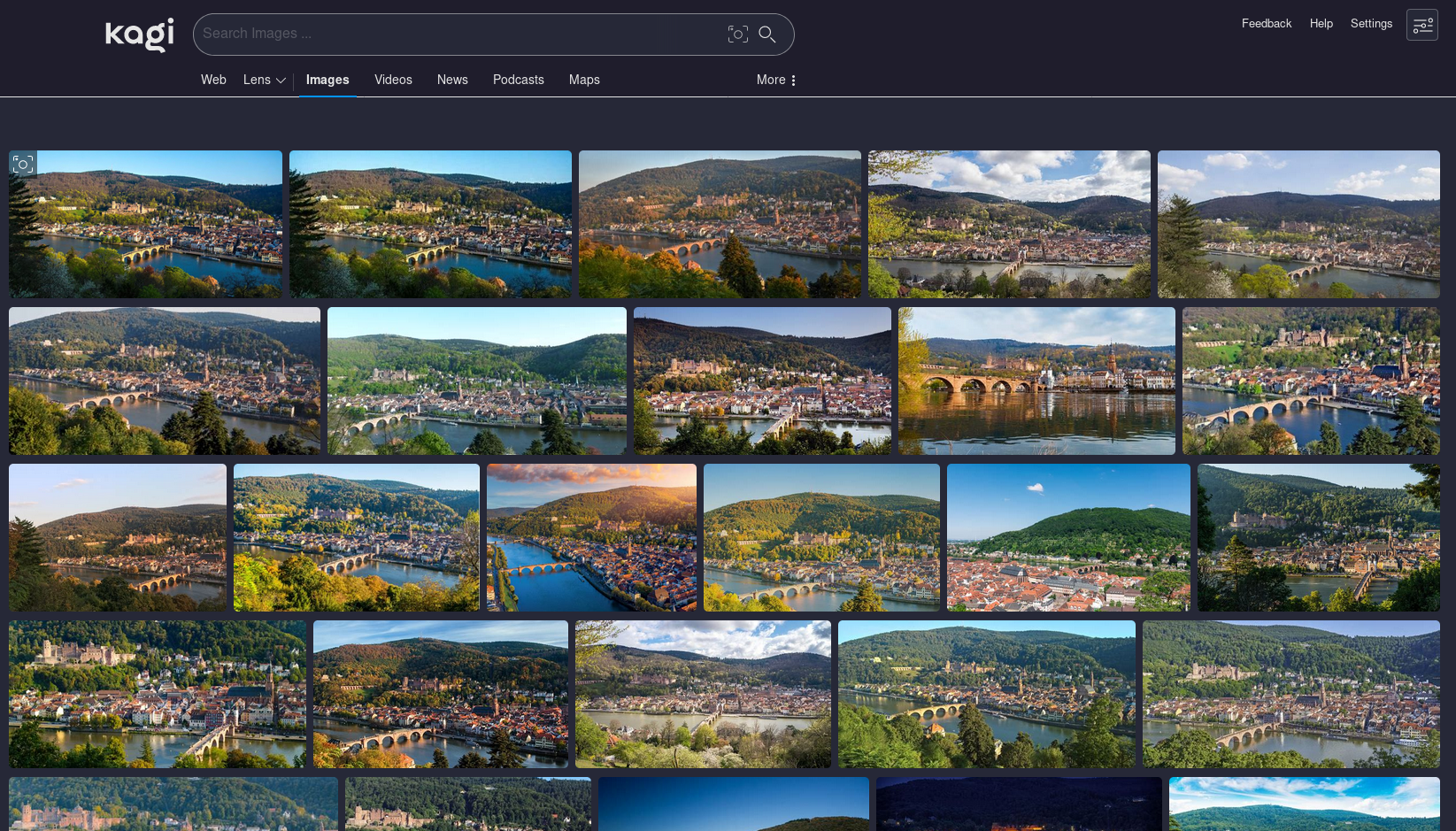
Trying again with copious JPEG, Kagi’s results barely changed at all. The same pic was still top.
Pretty solid win here.
Let’s test Google Lens! It finds similar but not identical images, and tries to sell me prints of this view of Heidelberg.
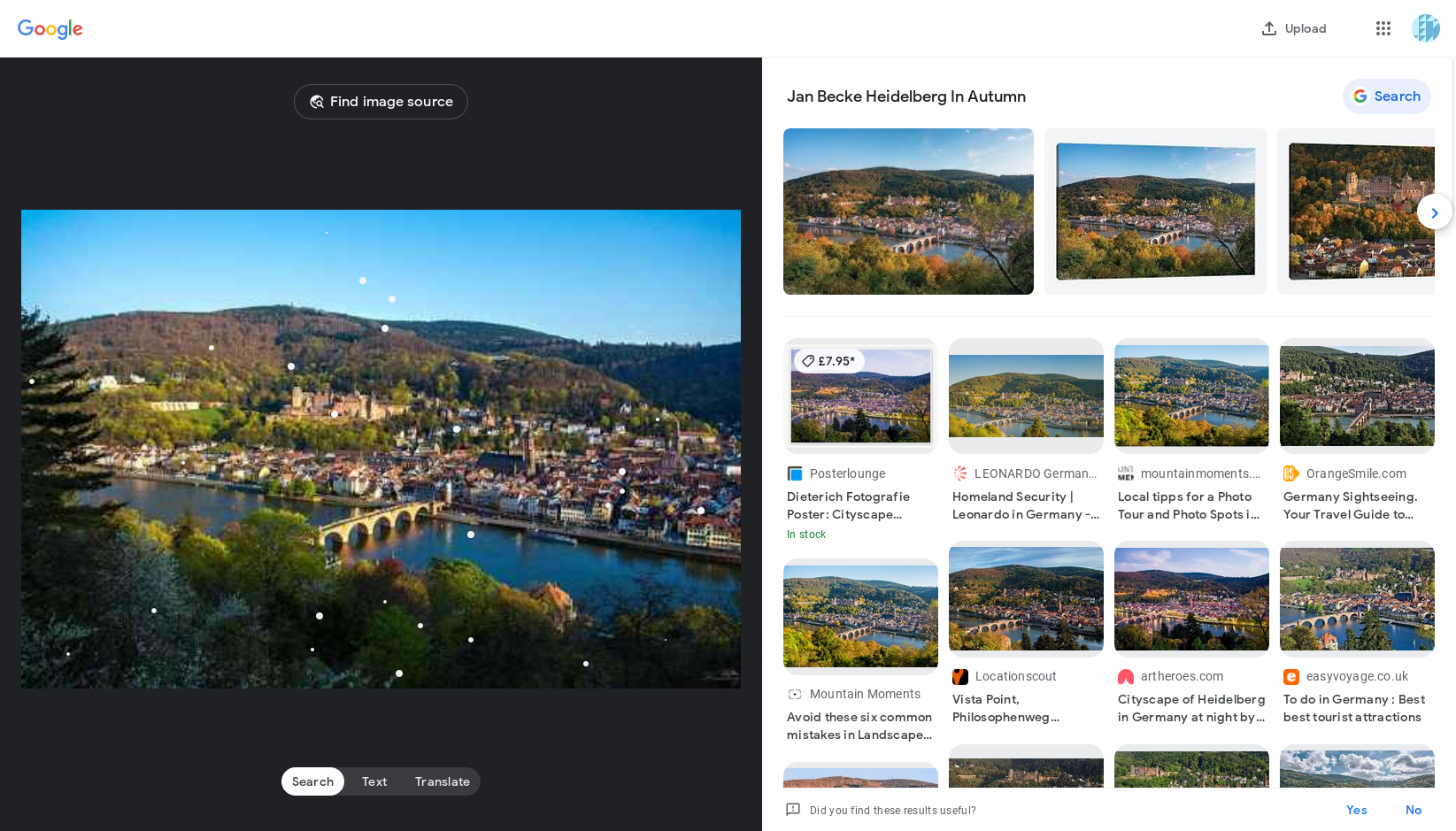
Asking for the image source fails to find it at all. Fail for Google here on getting the source.
If you did want a pretty picture of Heidelberg then here’s a pic that Google thinks is the same as the one I gave it, in 4K, on Wikimedia Commons. https://commons.wikimedia.org/wiki/File:Heidelberg_from_Philosophenweg.jpg
{kind=link}
The compressed version yielded the same result.
Testing on Yandex next, it finds very similar results to Google, including that picture from Wikimedia Commons!
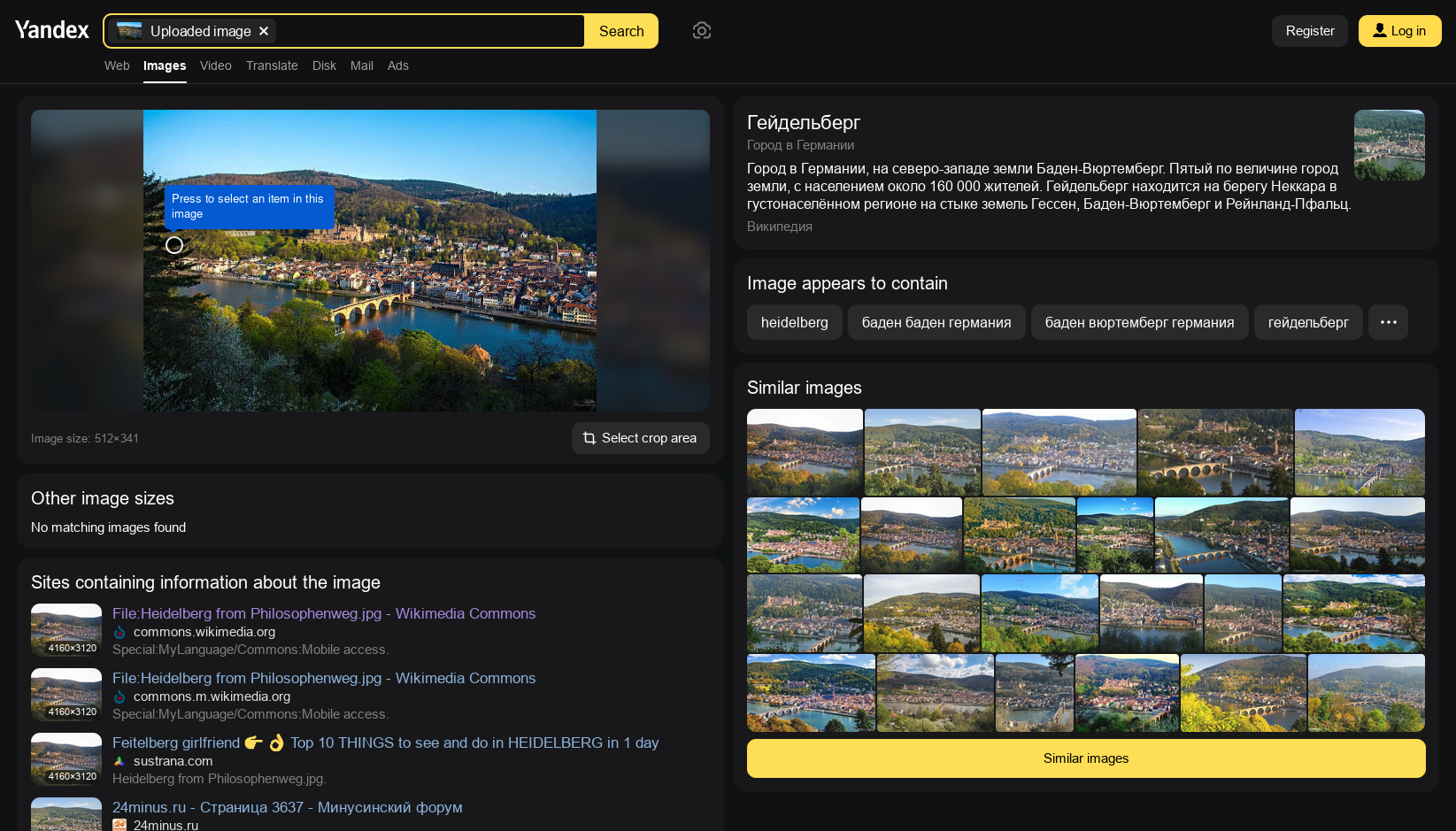
Yandex gets a bonus point for identifying this as Heidelberg and showing a fact file popup.

Bing found the same Pinterest post as Kagi, which I’m going to call a win here. Uniquely, Bing also are entirely impervious to JPEG compression here too, yielding identical results. Maybe some AI voodoo going on with Microsoft’s investment in OpenAI and Bing Chat?

Conclusion
Kagi does have one key advantage here, though, its ad-free without an ad blocker, which is pretty key. And its “fine” enough that I could use it.
I am going to continue using Kagi as my search engine until my trial 100 searches run out. I guess that’ll last me until at least the end of this month?
When that happens, I’ll leave my overall thoughts on my trial here. I hope it can pleasantly surprise me beyond what I’ve found here.
I’m honestly kind of surprised by Google’s showing here. Their results aren’t perfect, and I still think I would rather use Qwant than Google, but they’re clearly the industry leaders for a reason.
If you’re looking for reverse image search, Kagi put up an impressive performance, comparatively, though the undisputable king of reverse image search has to be Bing, despite my hunch that it’d be Yandex. Nice bonus point for them here.
In conclusion, Kagi is | MY THOUGHTS ON KAGI WHEN I RUN OUT OF SEARCHES WILL GO HERE |
Thanks for reading
— sink